
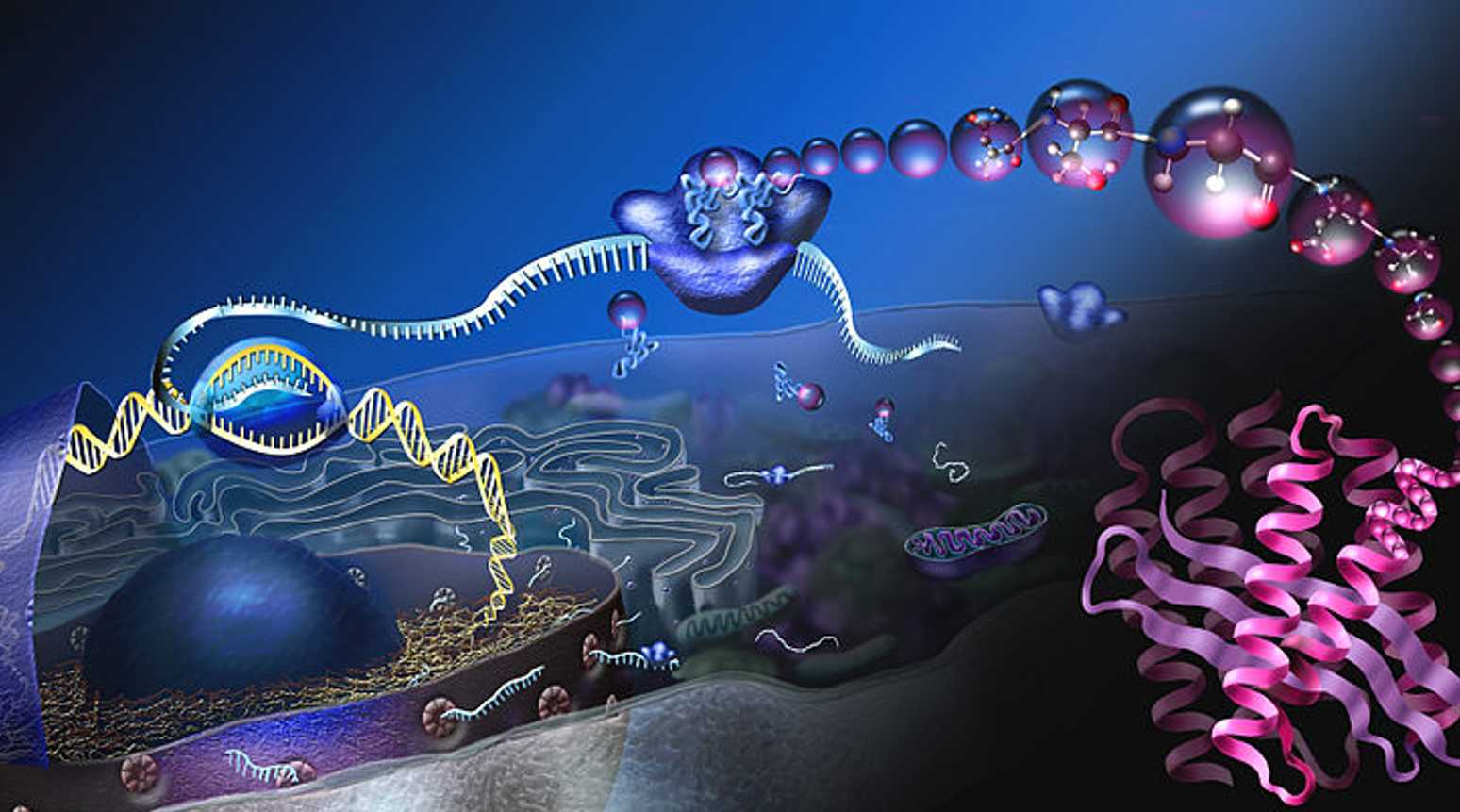
Este texto seguinte é sobre o tema: Síntese proteica, é bastante importante para a prova do ENEM, e vamos estudar.
Nem todos os aminoácidos são produzidos pelo corpo, outros aminoácidos são obtidos pela dieta. Dentro das células, as proteínas são geradas envolvendo processos de transcrição e tradução. Em resumo, a transcrição é o processo pelo qual o modelo de mRNA é transcrito a partir do DNA.
O modelo é usado para o passo seguinte, a tradução. Na tradução, os aminoácidos são ligados em uma ordem específica com base no código genético. Após a tradução, a proteína recém-formada passa por processos adicionais, como proteólise, modificação pós-traducional e dobramento de proteínas.
Definição de Síntese de Proteínas
A síntese de proteínas é a criação de proteínas. Nos sistemas biológicos, ela é realizada dentro da célula. Em procariotos, ocorre no citoplasma. Em eucariotos, inicialmente ocorre no núcleo para criar um transcrito (mRNA) da região codificadora do DNA. O transcrito deixa o núcleo e alcança os ribossomos para tradução em uma molécula de proteína com uma sequência específica de aminoácidos.
A síntese de proteínas é a criação de proteínas pelas células que usa DNA, RNA e vários enzimas. Geralmente inclui transcrição, tradução e eventos pós-traducionais, como dobramento de proteínas, modificações e proteólise.
Síntese de Proteínas em Procariotos e Eucariotos
As proteínas são um grande tipo de biomolécula que todos os seres vivos necessitam para prosperar. Tanto procariotos quanto eucariotos produzem várias proteínas para processos e funções multifários. Algumas proteínas são usadas para fins estruturais, enquanto outras atuam como catalisadores para reações bioquímicas.
As sínteses de proteínas em procariotos e eucariotos têm diferenças distintas. Por exemplo, a síntese de proteínas em procariotos ocorre no citoplasma. Em eucariotos, o primeiro passo (transcrição) ocorre no núcleo. Quando o transcrito (mRNA) é formado, ele passa para o citoplasma onde os ribossomos estão localizados.
Passos da Biossíntese de Proteínas
A síntese de proteínas nas células é um processo de duas etapas: transcrição e tradução.
Transcrição
A transcrição é o processo pelo qual um modelo de mRNA, codificando a sequência da proteína na forma de um código trinucleotídico, é transcrito do DNA para fornecer um modelo para tradução com a ajuda da enzima RNA polimerase.
Assim, a transcrição é considerada o primeiro passo da expressão gênica. Semelhante à replicação do DNA, a transcrição ocorre na mesma direção. Mas ao contrário da replicação do DNA, a transcrição não precisa de um iniciador para iniciar o processo e, em vez de timina, uracila se emparelha com adenina.
Os passos da transcrição são os seguintes: Iniciação -> Escape do promotor -> Alongamento -> Término.
Tradução
A tradução é o processo no qual os aminoácidos são ligados em uma ordem específica de acordo com as regras especificadas pelo código genético. Ela ocorre no citoplasma onde os ribossomos estão localizados. Consiste em quatro fases:
- Ativação (o aminoácido é ligado covalentemente ao tRNA),
- Iniciação (a subunidade pequena do ribossomo se liga ao 5′ do mRNA com a ajuda de fatores de iniciação)
- Alongamento (o próximo aminoacil-tRNA na fila se liga ao ribossomo junto com GTP e um fator de elongação)
- Término (o sítio A do ribossomo enfrenta um códon de parada)
Onde ocorre a síntese de proteínas em procariotos?
Os procariotos têm ribossomos 70S com subunidades 50S e 30S. Os ribossomos são encontrados livremente em abundância no citoplasma da célula procariótica. Com a discussão acima, agora sabemos que os ribossomos são a fábrica de proteínas da célula. Com base no local dos ribossomos em uma célula procariótica, podemos afirmar com segurança que a síntese de proteínas procarióticas ocorre no citoplasma da célula.
Onde ocorre a síntese de proteínas em eucariotos?
A partir da discussão acima, fica claro que a disponibilidade/localização dos ribossomos eventualmente determina o local da síntese de proteínas em uma célula. O ribossomo eucariótico é um grande tipo 80S e é composto por subunidades 60S e 40S. O nucléolo é o local de síntese do ribossomo em uma célula eucariótica.
Ao contrário dos procariotos, os ribossomos não se limitam apenas ao citoplasma nos eucariotos; eles também são encontrados nas mitocôndrias e no retículo endoplasmático (RE).
Isso nos leva à resposta a uma pergunta comum – As mitocôndrias possuem ribossomos? A resposta para isso é – Sim, as mitocôndrias possuem ribossomos.
Os ribossomos estão disponíveis livremente no citoplasma, bem como ligados ao RE em uma célula eucariótica. O RE é uma malha de túbulos ou sacos que se estendem da membrana nuclear ao citoplasma celular inteiro. Dependendo do tipo celular e de sua função, o tamanho do RE varia de célula para célula. Em termos simples, eu concluiria que, em células eucarióticas, os processos de síntese de proteínas ocorrem em diferentes locais celulares.
Qual é a sua opinião sobre isso? Deixe seu comentário.





Deixe um comentário